Add a const here, delete a const there…--Bruce Dawson

constexpr.
Add a const here, delete a const there…
by Bruce Dawson
From the article:
I just completed a series of changes that shrunk the Chrome browser’s on-disk size on Windows by over a megabyte, moved about 500 KB of data from its read/write data segments to its read-only data segments, and reduced its private working set by about 200 KB per-process. The amusing thing about this series of changes is that they consisted entirely of removing const from some places, and adding const to others. Compilers be weird...
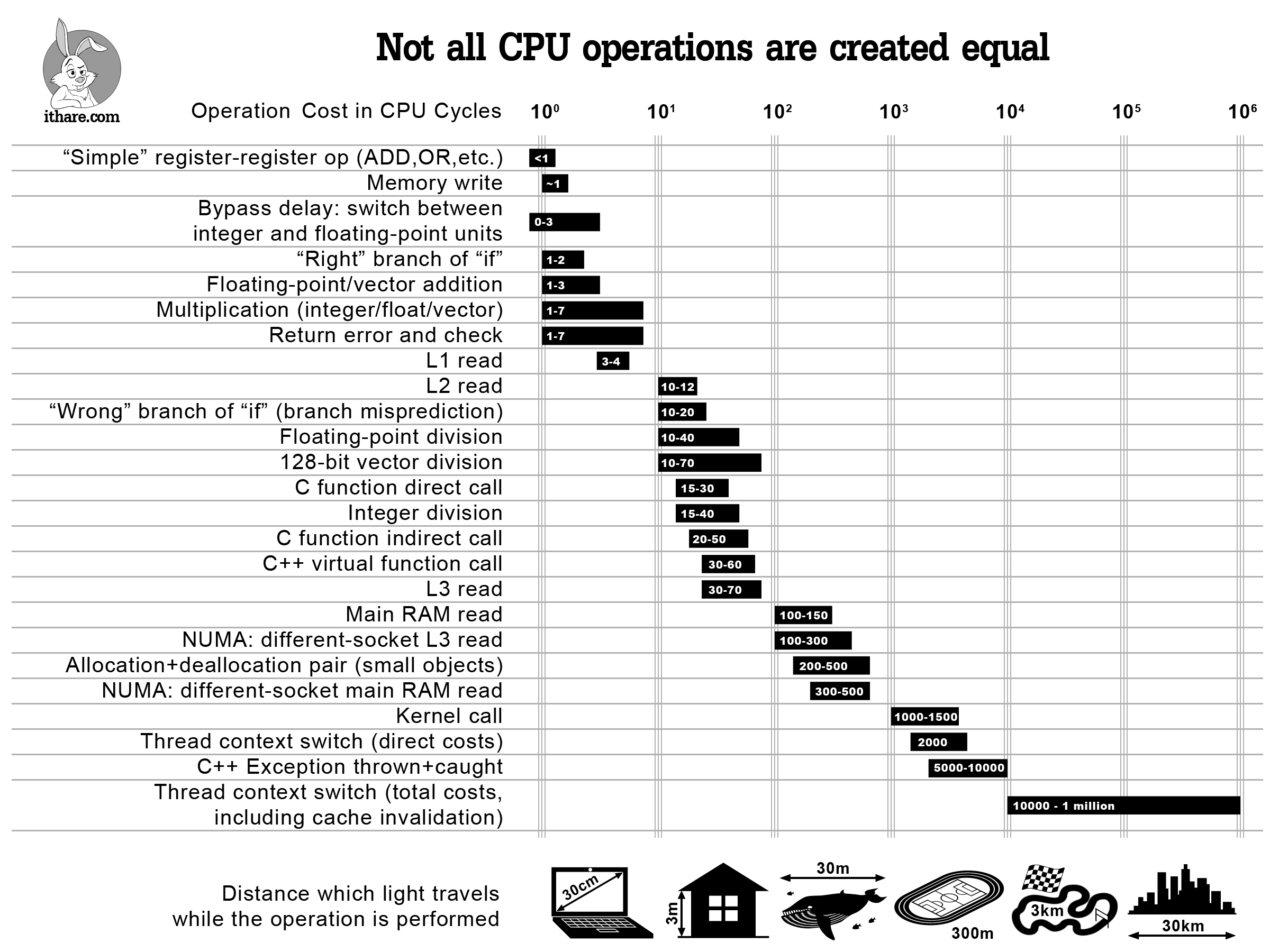 A very interesting article about the cost of our basic operations.
A very interesting article about the cost of our basic operations. The new GoingNative is out!
The new GoingNative is out!