C++26: More constexpr in the Core Language -- Sandor Dargo
 In this article, we review how
In this article, we review how constexpr evolves in the C++26 core language. We are getting constexpr cast from void*, placement new, structured bindings and even exceptions (not discussed today).
C++26: More constexpr in the Core Language
by Sandor Dargo
From the article:
Since
constexprwas added to the language in C++11, its scope has been gradually expanded. In the beginning, we couldn’t even useif,elseor loops, which were changed in C++14. C++17 added support forconstexprlambdas. C++20 added the ability to use allocation and usestd::vectorandstd::stringin constant expressions. In this article, let’s see how constexpr evolves with C++26. To be more punctual, let’s see what language features become moreconstexpr-friendly. We’ll discuss library changes in a separate article, as well asconstexprexceptions, which need both language and library changes.P2738R1:
constexprcast fromvoid*Thanks to the acceptance of P2738R1, starting from C++26, one can cast from
void*to a pointer of typeTin constant expressions, if the type of the object at that adress is exactly the type ofT.Note that conversions to interconvertible - including pointers to base classes - or not related types are not permitted.
The motivation behind this change is to make several standard library functions or types work at compile time. To name a few examples: std::format, std::function, std::function_ref, std::any. The reason why this change will allow many more for more
constexprin the standard library is that storingvoid*is a commonly used compilation firewall technique to reduce template instantiations and the number of symbols in compiled binaries.
 Modern C++ offers a variety of ways to work with key-value data structures like
Modern C++ offers a variety of ways to work with key-value data structures like 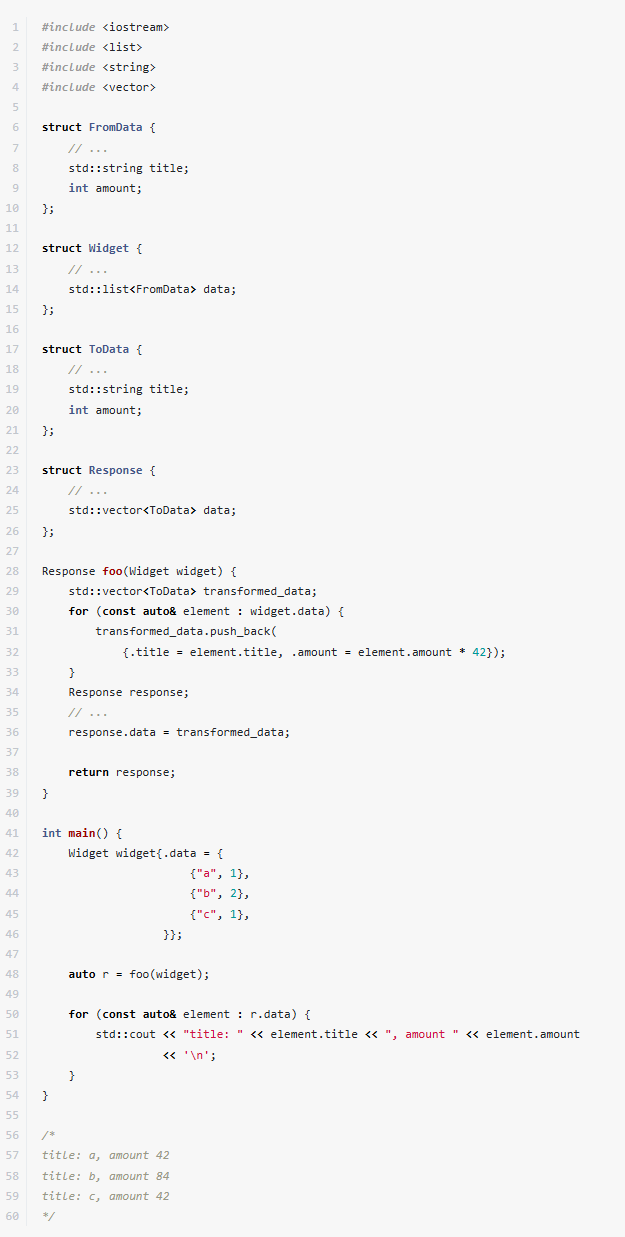
 Constexpr has been around for a while now, but many don’t fully understand its subtleties. Andreas Fertig explores its use and when a constexpr expression might not be evaluated at compile time.
Constexpr has been around for a while now, but many don’t fully understand its subtleties. Andreas Fertig explores its use and when a constexpr expression might not be evaluated at compile time. C++’s undefined behaviour impacts safety. Sandor Dargo explains how and why uninitialised reads will become erroneous behaviour in C++26, rather than being undefined behaviour.
C++’s undefined behaviour impacts safety. Sandor Dargo explains how and why uninitialised reads will become erroneous behaviour in C++26, rather than being undefined behaviour. In the December issue of Overload [
In the December issue of Overload [