Support for Android CMake projects in Visual Studio--Ion Todirel
 Discover a functionnality of Visual Studio:
Discover a functionnality of Visual Studio:
Support for Android CMake projects in Visual Studio
by Ion Todirel
From the article:
CMake is a cross-platform project generator that enables reuse of shared C++ code across multiple IDE and project systems.
We made a change to CMake to support our Android toolchain in Visual Studio. With this change, you can take your existing CMake project targetting Android, and with minimal modifications, you can have it open in Visual Studio, and benefit from our rich IDE experience for Android...

 Oracle Solaris Studio 12.5 Beta Release
Oracle Solaris Studio 12.5 Beta Release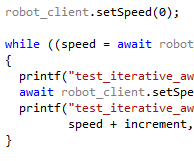 This article is considers lots of approaches to solving a concurrency problem, but of particular interest are the sections showing the power of the Concurrency TS
This article is considers lots of approaches to solving a concurrency problem, but of particular interest are the sections showing the power of the Concurrency TS