From the archives: "C++: as close as possible to C -- but no closer" -- A. Koenig and B. Stroustrup
 For your Friday reading pleasure, we recently came across one of the very earliest C++ standardization papers written, with number N0007 (or call it "007"):
For your Friday reading pleasure, we recently came across one of the very earliest C++ standardization papers written, with number N0007 (or call it "007"):
C++: as close as possible to C -- but no closer
by Andrew Koenig and Bjarne Stroustrup
It's interesting too see how much C++ has stayed true to its root design. And the thesis and contents of this paper are both remarkably current, and to be considered by those who would attempt to C-ify C++, or C++-ify C.
From the paper:
ANSI C and the C subset of C++ serve subtly different purposes. ...
The purpose of this note is to summarize the remaining differences between the draft ANSI C standard and C++, explain their motivation, and point out cases where these differences are less important than they might appear at first.

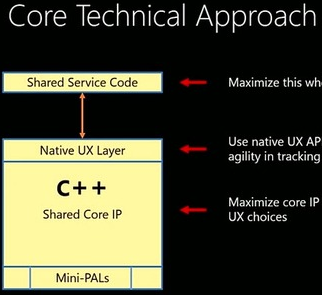 Modern C++, modern apps:
Modern C++, modern apps:
 Fresh over the weekend, and
Fresh over the weekend, and  Overload 123 is now available. It contains the following C++-related articles, and more:
Overload 123 is now available. It contains the following C++-related articles, and more: