CppCon 2025 Reflection: C++’s Decade-Defining Rocket Engine -- Herb Sutter
 Registration is now open for CppCon 2026! The conference starts on September 12 and will be held in person in Aurora, CO. To whet your appetite for this year’s conference, we’re posting videos of some of the top-rated talks from last year's conference. Here’s another CppCon talk video we hope you will enjoy – and why not register today for CppCon 2026!
Registration is now open for CppCon 2026! The conference starts on September 12 and will be held in person in Aurora, CO. To whet your appetite for this year’s conference, we’re posting videos of some of the top-rated talks from last year's conference. Here’s another CppCon talk video we hope you will enjoy – and why not register today for CppCon 2026!
Reflection: C++’s Decade-Defining Rocket Engine
by Herb Sutter
Summary of the talk:
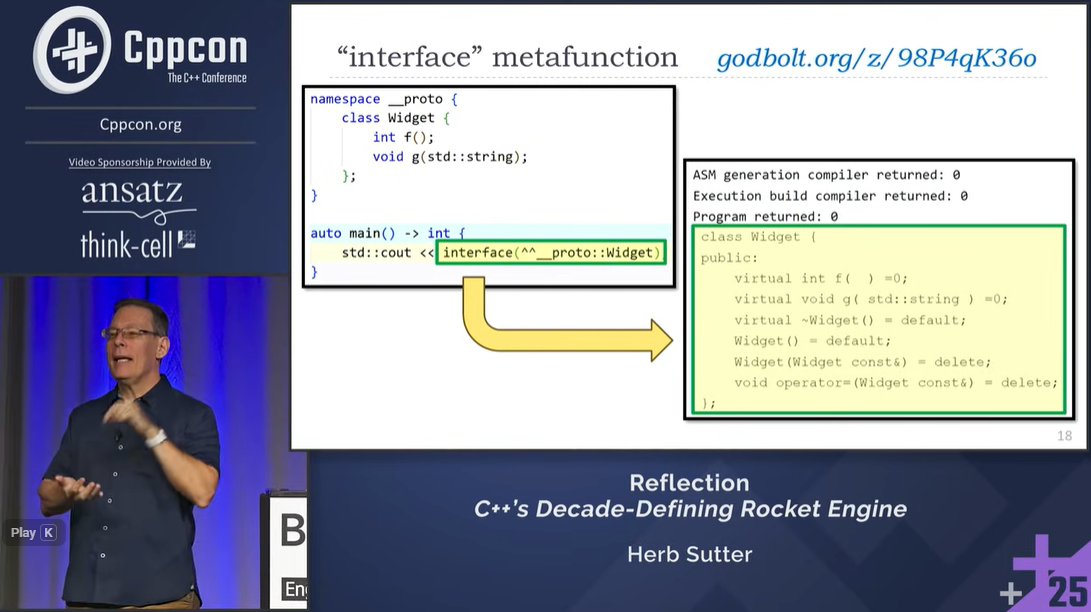
In June 2025, C++ crossed a Rubicon: it handed us the keys to its own machinery. For the first time, C++ can describe itself—and generate more. The first compile-time reflection features in draft C++26 mark the most transformative turning point in our language’s history by giving us the most powerful new engine for expressing efficient abstractions that C++ has ever had, and we’ll need the next decade to discover what this rocket can do.
This session is a high-velocity tour through what reflection enables today in C++26, and what it will enable next. We’ll start with live compiler demos (Godbolt, of course) to show how much the initial C++26 feature set can already do. Then we’ll jump a few years ahead, using Dan Katz’s Clang extensions and my own cppfront reflection implementation to preview future capabilities that could reshape not just C++, but the way we think about programming itself.
We’ll see how reflection can simplify C++’s future evolution by reducing the need for as many bespoke new language features, since many can now be expressed as reusable compile-time libraries—faster to design, easier to test, and portable from day one. We’ll even glimpse how it might solve a problem that has long eluded the entire software industry, in a way that benefits every language.
The point of this talk isn’t to immediately grok any given technique or example. The takeaway is bigger: to leave all of us dizzy from the sheer volume of different examples, asking again and again, “Wait, we can do that now?!”—to fire up our imaginations to discover and develop this enormous new frontier together, and chart the strange new worlds C++ reflection has just opened for us to explore.
Reflection has arrived, more is coming, and the frontier is open. Let’s go.
 Registration is now open for CppCon 2026! The conference starts on September 12 and will be held
Registration is now open for CppCon 2026! The conference starts on September 12 and will be held  Registration is now open for CppCon 2026! The conference starts on September 12 and will be held
Registration is now open for CppCon 2026! The conference starts on September 12 and will be held  C++26 is bringing some long-overdue changes to
C++26 is bringing some long-overdue changes to