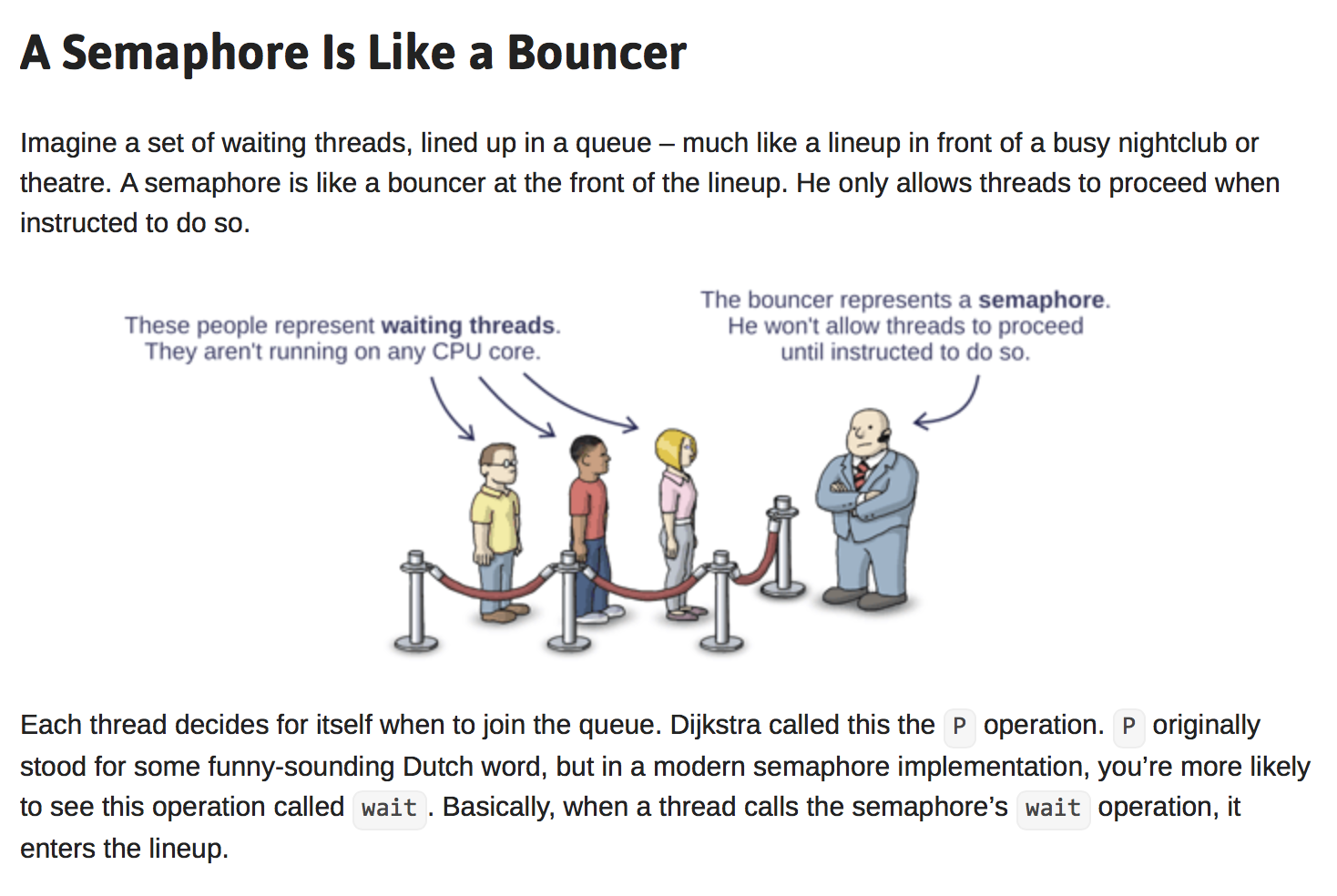
Multi-Dimensional Analog Literals -- Eelis
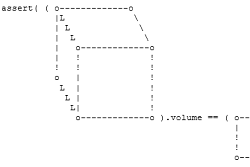 Demonstrating the power of C++11 user-defined literals:
Demonstrating the power of C++11 user-defined literals:
Multi-Dimensional Analog Literals
by Eelis
From the article:
Note: The following is all standard-conforming C++, this is not a hypothetical language extension...