More About Variadic Templates--Arne Mertz
Did you know?
More About Variadic Templates
by Arne Mertz
From the article:
I gave an introduction to variadic templates last week. Today I will talk about some more features that have or will be added in that area in C++11, 14 and 17.

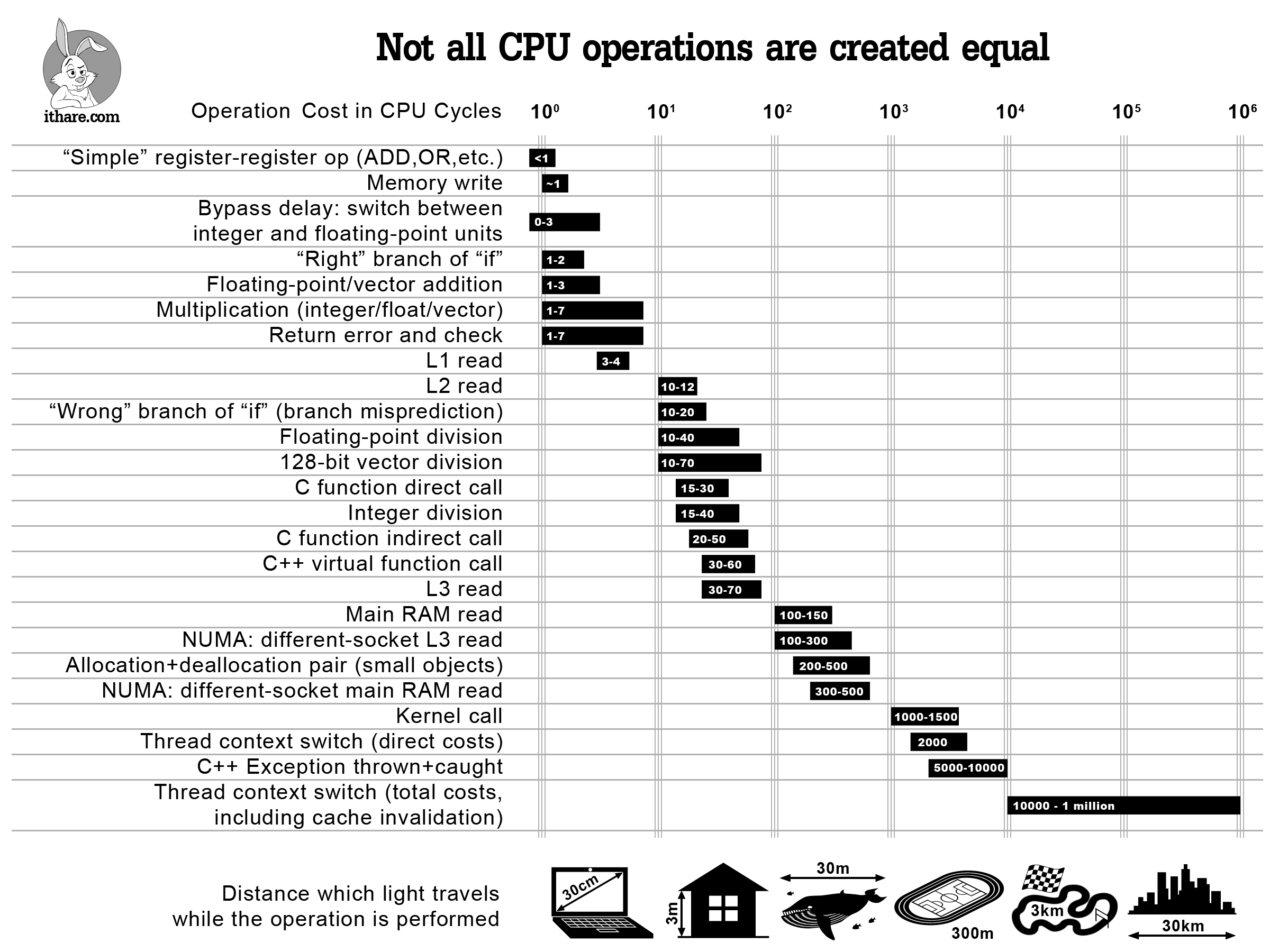 A very interesting article about the cost of our basic operations.
A very interesting article about the cost of our basic operations.