Quick Q: Does constexpr guarantee compile-time evaluation? -- StackOverflow
Quick A: constexpr guarantees compile-time evaluation is possible if operating on a compile-time value, and that compile-time evaluation will happen if a compile-time result is needed.
From SO, the originally worded question:
Can C++
constexprfunction actually accept non-constant expression as argument?I have defined a constexpr function as following:
constexpr int foo(int i) { return i*2; }And this is what in the main function:
int main() { int i=2; cout<<foo(i)<<endl; int arr[foo(i)]; for(int j=0;j<foo(i);j++) arr[j]=j; for(int j=0;j<foo(i);j++) cout<<arr[j]<<" "; cout<<endl; return 0; }The program was compiled under OS X 10.8 with command clang++. I was surprised that the compiler did not produce any error message about foo(i) not being a constant expression, and the compiled program actually worked fine. Why?

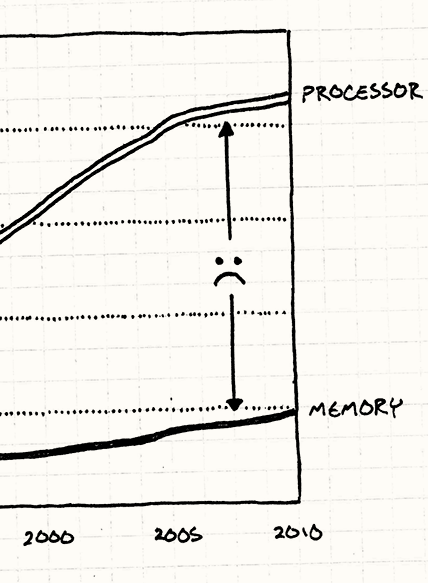 A nice refresher on data locality, and coding techniques to improve it for substantial performance gains.
A nice refresher on data locality, and coding techniques to improve it for substantial performance gains.{kind=link}