SObjectizer Tales - 8. Representing errors--Marco Arena
 A new episode of the series about SObjectizer and message passing:
A new episode of the series about SObjectizer and message passing:
SObjectizer Tales - 8. Representing errors
by Marco Arena
From the article:
In this episode we'll discuss how to model application errors and explore techniques for filtering messages within agents!
 How do you untie the knotty problem of complexity? Lucian Radu Teodorescu shows us how to divide and conquer difficult problems.
How do you untie the knotty problem of complexity? Lucian Radu Teodorescu shows us how to divide and conquer difficult problems. A new episode of the series about SObjectizer and message passing:
A new episode of the series about SObjectizer and message passing: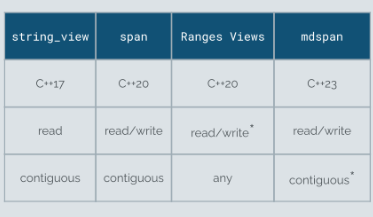 In this blog post, we’ll look at several different view/reference types introduced in Modern C++. The first one is
In this blog post, we’ll look at several different view/reference types introduced in Modern C++. The first one is  The Visual C++ team attended CppCon 2023, the largest in-person C++ conference, in Aurora, Colorado from October 2-6th. There were over 700 attendees from the C++ community, and we really enjoyed getting a chance to meet all of you and talk about your unique backgrounds and C++ experiences.
The Visual C++ team attended CppCon 2023, the largest in-person C++ conference, in Aurora, Colorado from October 2-6th. There were over 700 attendees from the C++ community, and we really enjoyed getting a chance to meet all of you and talk about your unique backgrounds and C++ experiences. A new episode of the series about SObjectizer and message passing:
A new episode of the series about SObjectizer and message passing: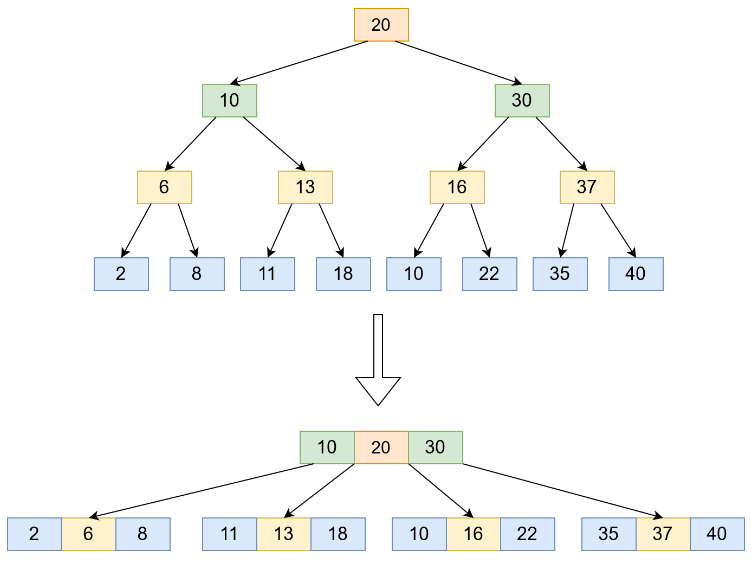 In this post we talk about how data structure data layout effects software performance and how, by modifying it, we can speed up the access and modification of the data structure.
In this post we talk about how data structure data layout effects software performance and how, by modifying it, we can speed up the access and modification of the data structure. A report out from this week's ISO C++ standards committee meeting, which just ended:
A report out from this week's ISO C++ standards committee meeting, which just ended: Learn how the overload pattern works for
Learn how the overload pattern works for