Quick Q: Does memory layout (including alignment) matter for performance? -- StackOverflow
Quick A: Oh, yeah.
See the nice three-paragaph "highlights" answer to the question:
Does alignment really matter for performance in C++11?
There is an advice in Stroustrup's book to order the members in a struct beginning from the biggest to the smallest. But I wonder if someone has made measurements to actually see if this makes any difference, and if it is worth it to think about when writing code.

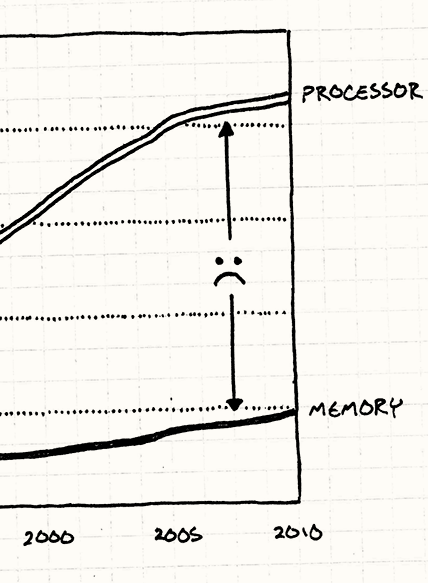 A nice refresher on data locality, and coding techniques to improve it for substantial performance gains.
A nice refresher on data locality, and coding techniques to improve it for substantial performance gains. In part 3, Andrzej turns to some practical use cases for type erasure.
In part 3, Andrzej turns to some practical use cases for type erasure. In part 1, Andrzej explained what "type erasure" is all about. But how do you create custom type-erased interface?
In part 1, Andrzej explained what "type erasure" is all about. But how do you create custom type-erased interface? A nice dive into performance costs on at least one compiler, and on the difficulties of doing meaningful performance measurements on modern hardware. Be sure to read the short comment thread too.
A nice dive into performance costs on at least one compiler, and on the difficulties of doing meaningful performance measurements on modern hardware. Be sure to read the short comment thread too. These are also the first two articles in a new blog by the creator of the
These are also the first two articles in a new blog by the creator of the {kind=link}