ACCU 2014 talk slides now available

[Ed: Here's a candidate for the most hilarious thing you'll probably see today: Kevlin Henney's slide deck, including a link to this @netbat tweet.]
The recent ACCU 2014 was another resounding success, and many of the talk slides have now been posted. You can find them here:
Slides, Photos, Blogs via #accu2014 (accu.org)
Some fun C++ highlights with slides available include:
- Dietmar Kuhl · Performance Choices
- Howard Hinnant · Everything You Ever Wanted To Know About Move Semantics (and then some)
- Hubert Matthews · Where is C++ headed?
- Jonathan Wakely · There Ain't No Such Thing As A Universal Reference
- Jonathan Wakely · The C++14 Standard Library
- Kevlin Henney · Immutabilty FTW!
- Marshall Clow · C++ Undefined Behavior -- what is it, and why should I care?
- Olve Maudal · C++ Pub Quiz
- Pattabi Raman · Random number generation in C++ -- present and potential future
- Peter Sommerlad · C++14 an overview on the new standard for C++(11) programmers
- Steve Love · Range and Elevation -- C++ in a modern world
- ... and more (see the page).
 Following up on Herb's three talk proposals posted yesterday, the other two titles and abstracts are now posted, this time of new talks (note: again, pending review and selection by the program committee, so this is not final -- they may or may not be selected if there is stronger material).
Following up on Herb's three talk proposals posted yesterday, the other two titles and abstracts are now posted, this time of new talks (note: again, pending review and selection by the program committee, so this is not final -- they may or may not be selected if there is stronger material). With the CppCon talk submission deadline upon us, we're starting to get glimpses of the potential CppCon conference program. In today's post, Herb Sutter mentions three of his five talk proposals (note: pending review and selection by the program committee, so this is not final -- they may or may not be selected if there is stronger material).
With the CppCon talk submission deadline upon us, we're starting to get glimpses of the potential CppCon conference program. In today's post, Herb Sutter mentions three of his five talk proposals (note: pending review and selection by the program committee, so this is not final -- they may or may not be selected if there is stronger material). At InformIT:
At InformIT: More rapid-fire "now write this using lambdas" problem-solution drill with Sumant Tambe:
More rapid-fire "now write this using lambdas" problem-solution drill with Sumant Tambe:
 Still on the theme of "contiguous enables fast," a followup on the recent "Fast Polymorphic Collections" article:
Still on the theme of "contiguous enables fast," a followup on the recent "Fast Polymorphic Collections" article: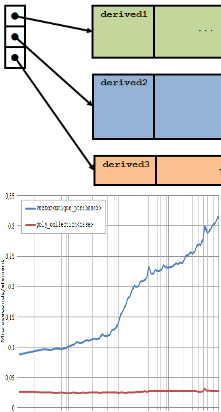 On the theme of "contiguous enables fast":
On the theme of "contiguous enables fast":