Trip Report: Fall ISO C++ Meeting in Wrocław, Poland -- Jonathan Müller
 Jonathan Müller attended the fall 2024 meeting of the ISO C++ standardization committee in Wrocław, Poland. This was the fifth meeting for the upcoming C++26 standard and the feature freeze for major C++26 features.
Jonathan Müller attended the fall 2024 meeting of the ISO C++ standardization committee in Wrocław, Poland. This was the fifth meeting for the upcoming C++26 standard and the feature freeze for major C++26 features.
Trip Report: Fall ISO C++ Meeting in Wrocław, Poland
by Jonathan Müller
From the article:
For an overview of all the papers that made progress, read Herb Sutter's trip report. Contracts and profiles are the big ticket items that made the most progress this meeting. Contracts is forwarded to wording review, while still being fiercely opposed by some. Profiles is essentially standardized static analysis to improve memory safety, although some deem it ineffective. Due to various scheduling conflicts I did not attend any of the relevant discussions in these spaces. Instead, I am going to share my thoughts about ranges, relocation, and reflection.
Ranges
I've spent the first day and a half co-chairing SG 9, the study group for
std::ranges. During discussions, we realized two big holes in the range library that we need to address as soon as possible. They both concern the concept of sized ranges.The first hole is related to proposal P3179—C++ parallel range algorithms, which adds an execution policy to the algorithms in
std::ranges. This makes it trivial to run multi-threaded algorithms: Instead of writingstd::ranges::transform(vec, output, fn), you writestd::ranges::transform(std::execution::par, vec, output, fn)and now your input is split into multiple chunks and processed in parallel.
 The
The  In this article, we'll learn about
In this article, we'll learn about  While most time zones use simple hour offsets from UTC, some regions have chosen unusual time differences. In this blog post, we’ll explore how we can discover such zones using C++20’s chrono library.
While most time zones use simple hour offsets from UTC, some regions have chosen unusual time differences. In this blog post, we’ll explore how we can discover such zones using C++20’s chrono library.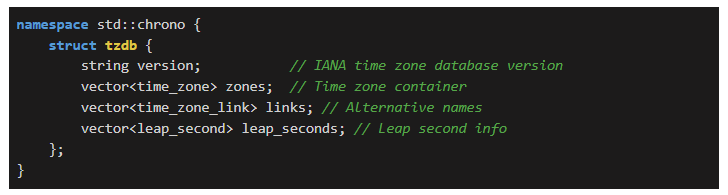
 In this blog post, we will explore handling dates using std::chrono, including time zones. We’ll utilize the latest features of the library to retrieve the current time across various time zones, taking into account daylight saving time changes as well. Additionally, we will incorporate new capabilities introduced in C++23, such as enhanced printing functions and more.
In this blog post, we will explore handling dates using std::chrono, including time zones. We’ll utilize the latest features of the library to retrieve the current time across various time zones, taking into account daylight saving time changes as well. Additionally, we will incorporate new capabilities introduced in C++23, such as enhanced printing functions and more. Recent versions of the C++ language (C++20 and C++23) may allow you to change drastically how you program in C++. I want to provide some fun examples.
Recent versions of the C++ language (C++20 and C++23) may allow you to change drastically how you program in C++. I want to provide some fun examples.