A Guest Editorial -- Quasar Chunawala, Frances Buontempo
 C++20 introduced coroutines. Quasar Chunawala, our guest editor for this edition, gives an overview.
C++20 introduced coroutines. Quasar Chunawala, our guest editor for this edition, gives an overview.
A Guest Editorial
by Quasar Chunawala, Frances Buontempo
From the article:
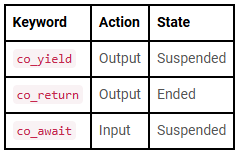
You’ve likely heard about this new C++20 feature, coroutines. I think that this is a really important subject and there are several cool use-cases for coroutines. A coroutine in the simplest terms is just a function that you can pause in the middle. At a later point the caller will decide to resume the execution of the function right where you left off. Unlike a function therefore, coroutines are always stateful - you at least need to remember where you left off in the function body.
Coroutines can simplify our code! Coroutines are a great tool, when it comes to implementing parsers.
The coroutine return type
The initial call to the coroutine function will produce a return object of a certain
ReturnTypeand hand it back to the caller. The interface of this type is what is going to determine what the coroutine is capable of. Since coroutines are super-flexible, we can do a whole lot with this return object. If you have some coroutine, and you want to understand what it’s doing, the first thing you should look at is theReturnType, and what it’s interface is. The important thing here is, we design thisReturnType. If you are writing a coroutine, you can decide what goes into this interface.
 std::chrono::high_resolution_clock sounds like the obvious choice when you care about precision, but its name hides some important caveats. In this article, we’ll demystify what “high resolution” really means in <chrono>, why this clock is often just an alias, and when—if ever—it’s actually the right tool to use.
std::chrono::high_resolution_clock sounds like the obvious choice when you care about precision, but its name hides some important caveats. In this article, we’ll demystify what “high resolution” really means in <chrono>, why this clock is often just an alias, and when—if ever—it’s actually the right tool to use.{kind=link}
{kind=link}