Embedding (and Extracting) DLLs into EXEs as Binary Resources -- Giovanni Dicanio
Windows EXE files can contain resources, including binary resources. In particular, you can embedd one or more DLLs into an EXE, and then extract them at run-time. Let's learn more about that in the following article:
Embedding (and Extracting) Binary Files like DLLs into an EXE as Resources
by Giovanni Dicanio
From the article:
A Windows .EXE executable file can contain binary resources, which are basically arbitrary binary data embedded in the file.
In particular, it’s possible to embed one or more DLLs as binary resources into an EXE. In this article, I’ll first show you how to embed a DLL as a binary resource into an EXE using the Visual Studio IDE; then, you’ll learn how to access that binary resource data using proper Windows API calls.
(...)
Once you have embedded a binary resource, like a DLL, into your EXE, you can access the resource’s binary data using some specific Windows APIs. (...)
The above “API dance” can be translated into the following C++ code: (...)
I uploaded on GitHub a C++ demo code that extracts a DLL embedded as a resource in the EXE, and, for testing purposes, invokes a function exported from the extracted DLL.
 The last episode of the series about SObjectizer and message passing:
The last episode of the series about SObjectizer and message passing: During the last two weeks, we saw a bug related to uninitialized values and undefined behaviour, we listed the different kinds of initializations in C++ and we started to more detailed discovery with copy-initialization. This week, we continue this discovery with direct-, list- and aggregate-initialization.
During the last two weeks, we saw a bug related to uninitialized values and undefined behaviour, we listed the different kinds of initializations in C++ and we started to more detailed discovery with copy-initialization. This week, we continue this discovery with direct-, list- and aggregate-initialization.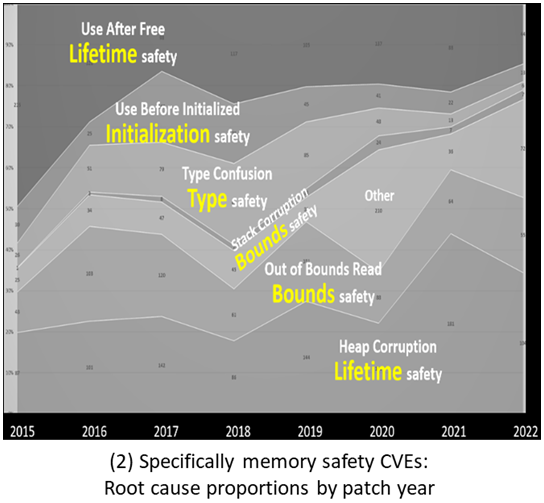 The safety of C++ has become a hot topic recently. Herb Sutter discusses the language’s current problems and potential solutions.
The safety of C++ has become a hot topic recently. Herb Sutter discusses the language’s current problems and potential solutions. A new episode of the series about SObjectizer and message passing:
A new episode of the series about SObjectizer and message passing: A new episode of the series about SObjectizer and message passing:
A new episode of the series about SObjectizer and message passing: A new episode of the series about SObjectizer and message passing:
A new episode of the series about SObjectizer and message passing: