What reinterpret_cast doesn't do -- Andreas Fertig
 In today's post, I will explain one of C++'s biggest pitfalls:
In today's post, I will explain one of C++'s biggest pitfalls: reinterpret_cast. Another title for this post could be: This is not the cast you're looking for!
What reinterpret_cast doesn't do
Andreas Fertig
From the article:
My motivation for this blog post comes from multiple training classes I thought over the past several months and a couple of talks I gave. Since C++23, you have a new facility in the Standard Library:
std::start_lifetime_as. When teaching class with a focus on embedded environments or presenting talks with such a focus, I started to addstd::start_lifetime_asto the material. With an interesting outcome.The feedback I get is roughly:
- why do I need
std::start_lifetime_as, I already havereinterpret_cast?- why can I use
reinterpret_cast?If you never heard of
start_lifetime_asplease consider reading my post, The correct way to do type punning in C++ - The second act.
 Even experienced C++ developers sometimes stumble on a deceptively simple question: what actually happens when a destructor throws an exception? This post breaks down the mechanics behind stack unwinding,
Even experienced C++ developers sometimes stumble on a deceptively simple question: what actually happens when a destructor throws an exception? This post breaks down the mechanics behind stack unwinding, 
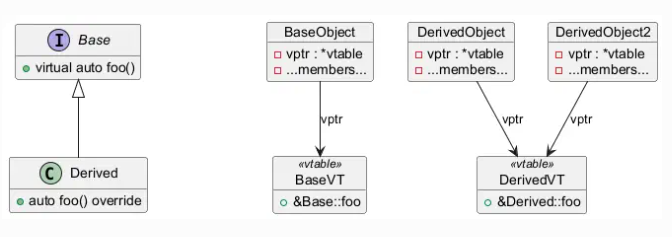 Ever wondered why your clean, object-oriented design sometimes slows things down? This piece breaks down how virtual dispatch impacts performance—and how techniques like devirtualization and static polymorphism can eliminate that overhead entirely.
Ever wondered why your clean, object-oriented design sometimes slows things down? This piece breaks down how virtual dispatch impacts performance—and how techniques like devirtualization and static polymorphism can eliminate that overhead entirely.