Discovering Observers - Part 3 -- Sandor Dargo
 Over the last two posts, we explored different implementations of the observer pattern in C++. We began with a very simple example, then evolved toward a more flexible, template- and inheritance-based design.
Over the last two posts, we explored different implementations of the observer pattern in C++. We began with a very simple example, then evolved toward a more flexible, template- and inheritance-based design.
This week, let’s move further — shifting away from inheritance and embracing composition.
Discovering Observers - Part 3
by Sandor Dargo
From the article:
You might say (and you’d be right) that publishers and subscribers can just as well be used as members instead of base classes. In fact, with our previous implementation, handling changes inside subscribers felt more complicated than necessary.
What we’d really like is this: subscribers that observe changes and trigger updates in their enclosing class in a coherent way. As one of the readers of Part 1 pointed out, this can be elegantly achieved if subscribers take callables.
Step 1: Subscribers with callables
We start by letting
Subscriberaccept astd::function, which gets called whenever the subscriber is updated:
 When you pass an overloaded function like
When you pass an overloaded function like 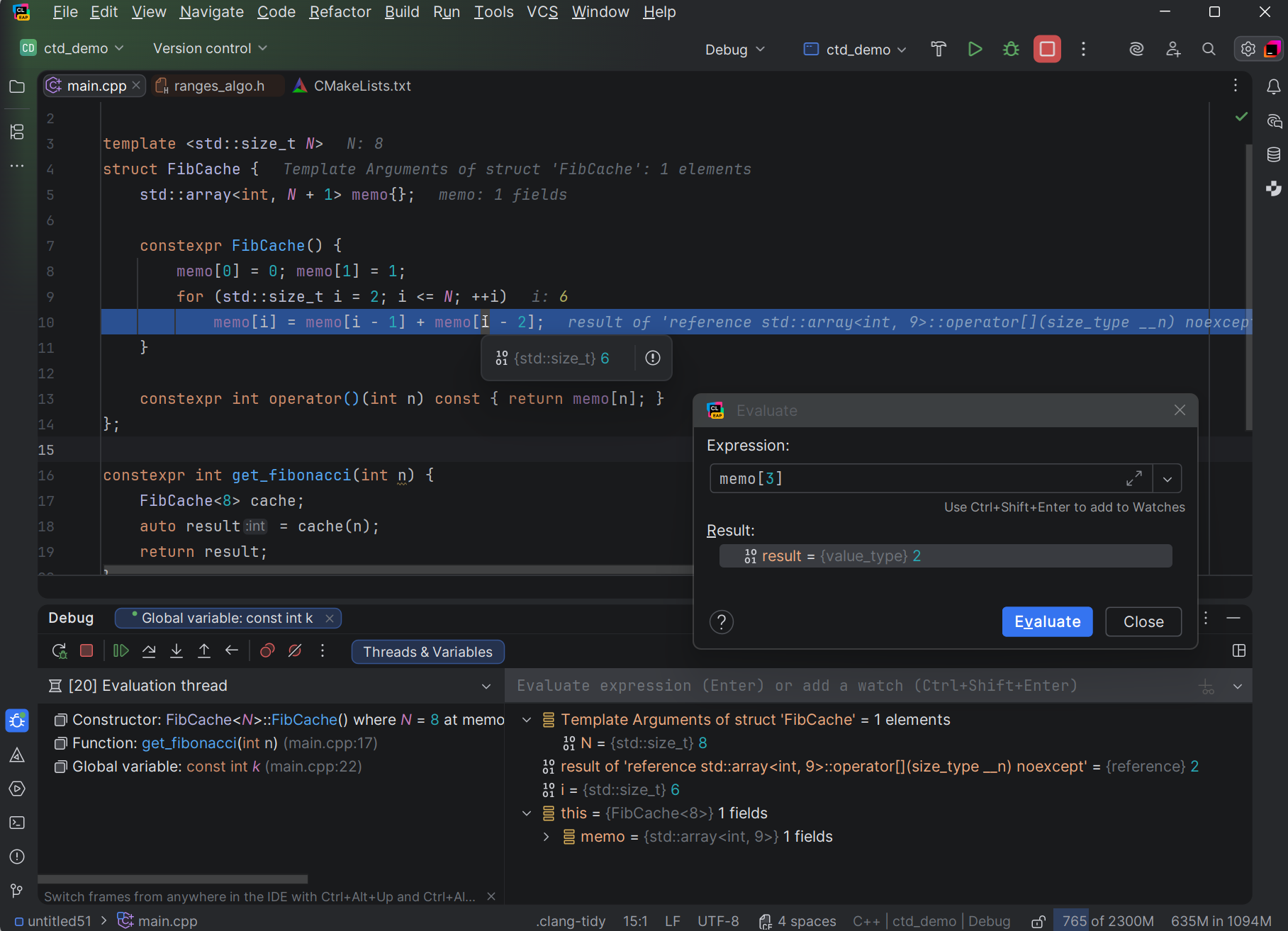 The new Constexpr Debugger available in the first CLion 2025.3 EAP build allows you to stay in the compiler’s world and see what really happens – by stepping through evaluation, inspecting values, and confirming which if constexpr branch fired. Using it helps you understand exactly what the compiler is doing and fix issues faster.
The new Constexpr Debugger available in the first CLion 2025.3 EAP build allows you to stay in the compiler’s world and see what really happens – by stepping through evaluation, inspecting values, and confirming which if constexpr branch fired. Using it helps you understand exactly what the compiler is doing and fix issues faster. A long-delayed dream finally came true: after years of near-misses and lessons learned (“better to be invited than sent”), I made it to CppCon—and it was bigger, louder, and more inspiring than I imagined. In this recap I share the vibe of the week, five standout talks and ideas, a few notes from my own session, and links to recordings as they appear.
A long-delayed dream finally came true: after years of near-misses and lessons learned (“better to be invited than sent”), I made it to CppCon—and it was bigger, louder, and more inspiring than I imagined. In this recap I share the vibe of the week, five standout talks and ideas, a few notes from my own session, and links to recordings as they appear. Structured binding is a C++17 feature that allows you to bind multiple variables to the elements of a structured object, such as a tuple or struct. This can make your code more concise and easier to read, especially when working with complex data structures. On this blog, we already covered this functionality, but we’ll talk about some good C++26 additions and real code use cases.
Structured binding is a C++17 feature that allows you to bind multiple variables to the elements of a structured object, such as a tuple or struct. This can make your code more concise and easier to read, especially when working with complex data structures. On this blog, we already covered this functionality, but we’ll talk about some good C++26 additions and real code use cases.