Singleton done right in C++ -- Andreas Fertig
 In today's post, I like to touch on a controversial topic: singletons. While I think it is best to have a codebase without singletons, the real-world shows me that singletons are often part of codebases.
In today's post, I like to touch on a controversial topic: singletons. While I think it is best to have a codebase without singletons, the real-world shows me that singletons are often part of codebases.
Singleton done right in C++
by Andreas Fertig
From the article:
Let's use a usage pattern for a singleton that I see frequently, a system-wide logger. A simple implementation can look like the following code:
class Logger {
Logger() = default;public:
static Logger& Instance()
{
static Logger theOneAndOnlyLogger{};return theOneAndOnlyLogger;
}void Info(std::string_view msg) { std::print("Info: {}", msg); }
void Error(std::string_view msg) { std::print("Error: {}", msg); }
};The key parts for a singleton in C++ are that the constructor is private and an access function that is static. With that, you ensure that a singleton object, here Logger can only be constructed by calling Instance, essentially limiting the number of Logger objects to a single one.
You're using such a Logger like this:
Logger::Instance().Info("A test");
 Conferences are never just about the talks — they’re about time, travel, tradeoffs, and the people you meet along the way. After a year of attending several C++ events across formats and cities, this post is a personal look at how different conferences balance technical depth, community, and the experience of being there.
Conferences are never just about the talks — they’re about time, travel, tradeoffs, and the people you meet along the way. After a year of attending several C++ events across formats and cities, this post is a personal look at how different conferences balance technical depth, community, and the experience of being there.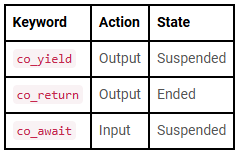 C++20 introduced coroutines. Quasar Chunawala, our guest editor for this edition, gives an overview.
C++20 introduced coroutines. Quasar Chunawala, our guest editor for this edition, gives an overview. std::chrono::high_resolution_clock sounds like the obvious choice when you care about precision, but its name hides some important caveats. In this article, we’ll demystify what “high resolution” really means in <chrono>, why this clock is often just an alias, and when—if ever—it’s actually the right tool to use.
std::chrono::high_resolution_clock sounds like the obvious choice when you care about precision, but its name hides some important caveats. In this article, we’ll demystify what “high resolution” really means in <chrono>, why this clock is often just an alias, and when—if ever—it’s actually the right tool to use.