using std::cpp 2026: Learning C++ as a newcomer - Berill Farkas
What does a 15 years old girl think about learning C++?
Summary of the talk:
How it feels like to learn C++ as a teenager? What made her want to learn it and what difficulties did she come across while learning it?
 Registration is now open for CppCon 2026! The conference starts on September 12 and will be held
Registration is now open for CppCon 2026! The conference starts on September 12 and will be held  Registration is now open for CppCon 2026! The conference starts on September 12 and will be held
Registration is now open for CppCon 2026! The conference starts on September 12 and will be held  In algorithmic trading, the Python-vs-C++ debate is usually framed as flexibility versus speed — rapid strategy development on one side, ultra-low-latency execution on the other. But with C++26 reflection, that trade-off starts to disappear, making it possible to generate Python bindings automatically while keeping the core logic running at native C++ performance.
In algorithmic trading, the Python-vs-C++ debate is usually framed as flexibility versus speed — rapid strategy development on one side, ultra-low-latency execution on the other. But with C++26 reflection, that trade-off starts to disappear, making it possible to generate Python bindings automatically while keeping the core logic running at native C++ performance. Registration is now open for CppCon 2026! The conference starts on September 12 and will be held
Registration is now open for CppCon 2026! The conference starts on September 12 and will be held 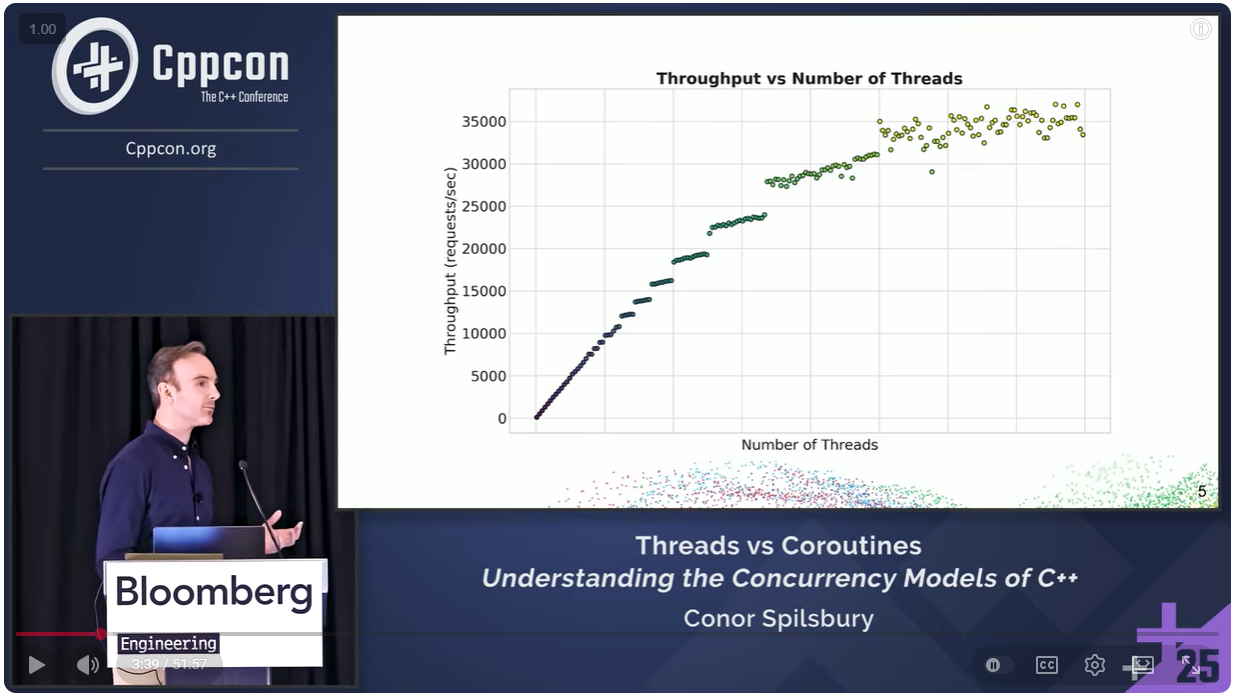 Registration is now open for CppCon 2026! The conference starts on September 12 and will be held
Registration is now open for CppCon 2026! The conference starts on September 12 and will be held